Overview of WORDij
WORDij is a suite of data science programs that automates many aspects of natural language processing. Unstructured text from sources such as social media, news, speeches, focus groups, interviews, email, web sites, and any text sources can be readily processed.
The software runs on Windows 32-bit and 64-bit, Mac 32-bit and 64-bit (See the FAQ about running macOS Catalina.)
WORDij runs very fast because the modules are written in C. Java is used only for the Graphical User Interface.
The suite can run data files as large as 550 megabytes with 8 gigabytes of RAM on a 64-bit machine. Small files with only 10s or 100s of documents can run in seconds.
Files analyzed are in UTF-8 format, so the programs handle languages with graphic characters such as Chinese, Japanese, Arabic, or Russian.
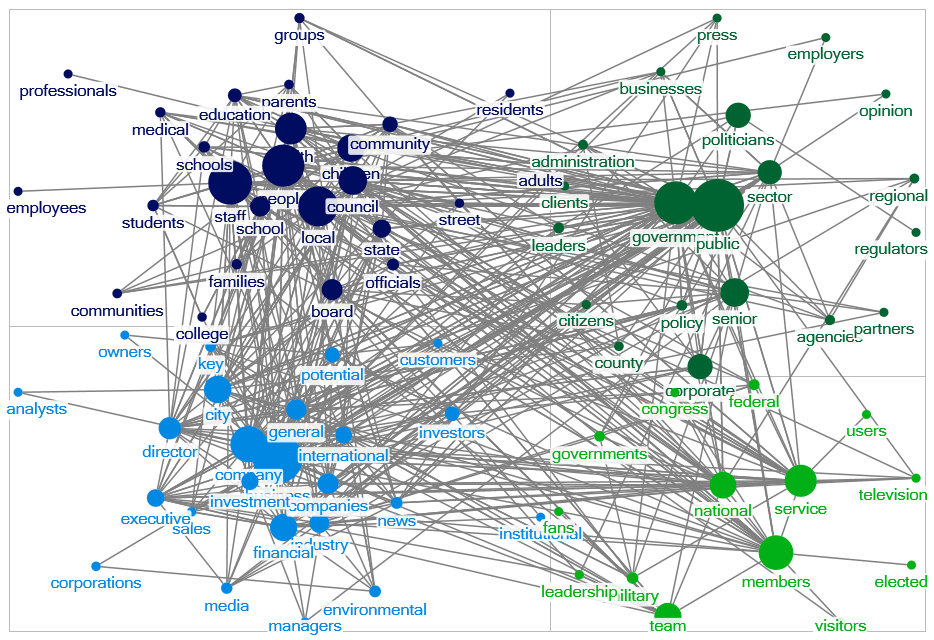
WordLink is the initial text processor. It moves a sliding window through text, centering on each word and tabulating directed word pair bigrams appearing three words before and three words afterward. By treating proximate words, WORDij is more precise than "bag of words" programs that treat all words in a document as related. WORDij preserves the order of words in a bigram, which embeds syntax effects. Directed bigrams are useful for the Opticomm software in WORDij, whose strings linking a seed word and target word then lead to near-grammatical statements.
String conversions are possible. One can convert multi-word phrases to a single unigram, such as "New York City" rendered as "new_york_city." As well, one can convert synonyms to a single unigram. Also enabled is creation and analysis of ontologies containing categories of words.
By using an "include list," the opposite of "drop list" or "stopword list," one can analyze networks among the included words. For example, an analyst can include a list of persons' names to find the network among them based on their cooccurrence in texts such as news stories. For another use of an include list, see the article in the Publications tab on "Scaling constructs with semantic networks." The publication demonstrates how to build an index for a construct using natural language, based on principal components analysis, taking the first eigenvector and its highly loading words to create an index.