Frequently Asked Questions
Question: "How should I cite WORDij?"
Answer: Cite the WORDij program as follows: Danowski, J. A. (2013). WORDij version 3.0: Semantic network analysis software. Chicago: University of Illinois at Chicago.
Question: "How do you pronounce WORDij?"
Answer:
First of all, WORDij has a double meaning. One sense is mathematical, hence the "i-j" as in a matrix notation for the ith and jth word. The other sense is as "wordage", in terms of a collection of words, words collectively, quantity or amount of words, or choice of words. https://www.dictionary.com/browse/wordage. James Danowski, the creator of WORDij, pronounces it like 'wordage,' it flows better and the meaning is richer, rather than 'word-i-j.' The double-entendre meaning creates the best of both worlds. The spelling conjures up the math meaning and the pronounciation creates a visualization of a big pile of words to be network analyzed!
Question: "What is WORDij?"
Answer:
WORDij is a text analysis program that treats words as nodes and word pairs as links for network analysis and other statistical analysis. The software runs on a PC, Mac and Linux system and is free for academic use.
WORDij has seven modules:
1. Wordlink: this is the base module which counts words and word pairs and the results are used by other modules.
2. QAPNet: calculates an overall measure of the similarity of two whole networks using a correlation coefficient from +1 to -1.
3. Z-Utilities compares two text files and determine what the significant differences there are for either the words or the word pairs.
4. VISij: a graphic visualization of words (nodes) and links. If multiple files are included an animation will play a network sequence change from one file to another.
5. OptiComm: produces messages to move two words closer, move them further apart, or to reinforce aspects of the semantic networks.
6. Utilities: A proper noun extraction and a TimeSegs program for over time analysis using input from Lexis/Nexis or NewsBank.
7. Conversions: converts WORDij files for use with MultiNet/Negopy UCINET, NetDraw and Pajek.
Question: How is WORDij different than traditional text coding?
Answer:

Question: "Does WORDij require any programing or coding?"
Answer: No. WORDij is a “point and click” menu driven software which does not require the user to be skilled in any special coding or programming language. WORDij does require text input in UTF-8 format, either in a TXT or CSV file. Mutliple files can be input at once.
Question: "What does the WORDij program user interface look like?"
Answer:
Here is a screenshot of the WORDij Software main menu.
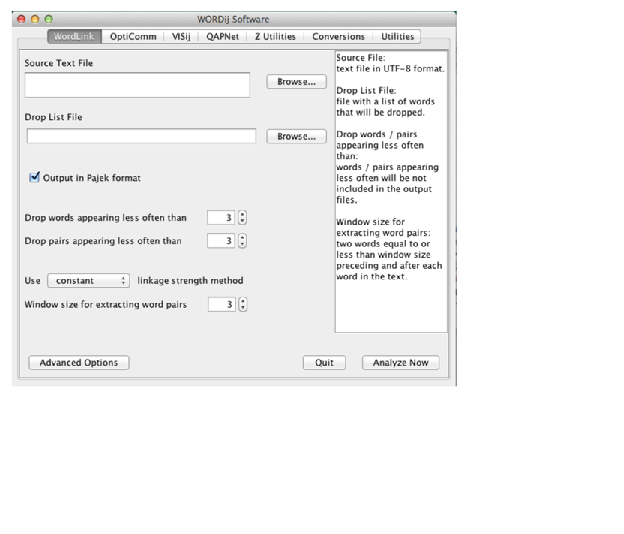
Question: "Is there documentation for the WORDij programs and options?"
Answer: Once you have downloaded WORDij, open the Documentation folder. There are 15 tutorials with extensive screenshots and instructions that give detailed information on running various procedures in the WORDij suite. 
Question: "Does WORDij need any auxiliary software for it to run?"
Answer: Yes, WORDij is a jar file and therefore needs the free Java Development Kit or JDK to run on a Mac or PC. You can download the Java JDK at: https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html.
Question: "Do you have any getting started tips?"
Answer:
Yes!
We suggest five getting started tips:
1. Show file extensions.
Why? Because WORDij’s Wordlink module produces 8 output files, all with a different
file extension. This helps to easily identify the file you wish to examine or use next.
a. On a Mac, open a Finder window, click Finder, select Preferences, click
Advanced, check the option to Show all filename extensions. 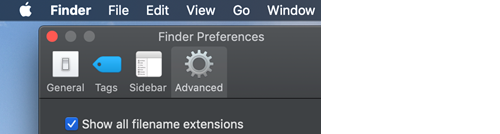
b. On a PC, open a Brower window, click View, check File name extensions. 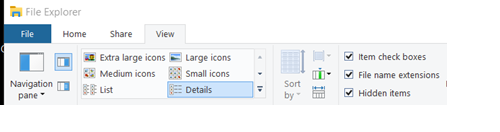
2. Create a new folder for your analysis.
WORDij produces many output files and having a unique folder for your projects
helps to keep all the files in one place.
3. Copy the drop list from the WORDij folder into your project folder.
Again, this helps for documentation to have all your files in one place, especially
if you decide to edit the drop list.
4. Have a Backup Plan for your project folder and files. Users have many backup
options today, such as syncing to a cloud storage, such as; Dropbox, Apple’s
iCloud, Windows Onedrive, or Google’s Drive. Or, simply use a USB drive to
copy your work.
5. Last if you wish to have text editor that works well for editing text files and works on a Mac or PC, we recommend
Sublimetext. Download at: https://www.sublimetext.com/3">
Question: "When should you reduce the default frequency of words, word pairs, and the slide window? Is there a rule of thumb between the number of words and the changing the default settings?"
Answer: The WORDij default settings are set to drop words appearing less often than 3 times and to drop word pairs less often than 3. These defaults work well for text with about 10 pages of text double spaced or about 5 pages of text single spaced which is about 2,500 words or greater. If you have less than 2,500 words, it is recommended to reduce the Drop word and Drop pairs to 2 or 1. If you have very large about of text you may wish to increase the drop limits to reduce the output.
Question: "What is meant by the “link strength”?"
Answer:
Link strength is how the distance between the word pairs are counted or weighted.
Constant means that no matter the size of the slide window a word pair will be always be counted as 1. A linear and exponential are two alternative weightings.
Below is an example of the three weights.

Question: "When should you change the default from “constant” to linear or exponential?"
Answer: It is a user’s personal preference when they should decide to change the link strength weight. If one changes the window size to be quite large, then linear or exponential weighting may be desirable.
Question:
"Why do you not recommend using the Porter stemming advanced option? Is there a case where you do recommend to stem?"
Answer: Our research has indicated that stemming may reduce the fine-grained interpretation of findings, and as a result, we prefer to not stem. However, stemming is an advanced option which may suit some user’s needs and it is available for use.
Question: "When trying to launch WORDij I get an error message, "A Java exception has occured. How do I fix this?"
Answer: This error occurs because you have not yet extracted the .zip file and are trying to start WORDij from within the .zip. To resolve this problem, extract the WORDij.zip file to a folder. Then when you click on WORDij, all will be well.
Question: "I get an error message Error: Internal error - failed to load required library. Error: java.lang.UnsatisfiedLinkError: Can't load library...wordlinklib.dll: can't find dependent libraries What should I do?"
Answer: This problem occurs with some Windows OS installations. A solution is to copy the file wordlinklib.dll in the folder: e.g. C:\***\WORDij30 for 64-bit Windows\libs\64 to the folder where the Java JDK executabiles are located: e.g C:\Program Files\Java\jdk1.8.0_191\bin.
Question:"When running WORDij programs I get an error message: Error: Failed to determine encoding. How can I resolve this error?"
Answer: Your file name has characters that WORDij doesn't like, hyphens (-). Rename your file to remove hyphens. Another item to check if on a mac is that you have converted the file to UTF-8 with BOM.
Question: "I have macOS Big Sur. How do I start WORDij?"
Answer: Once you have the JDK 8 installed, enter the terminal and change your directory using the "cd" command, then type: java -jar wordij.jar. That should start WORDij!
Question: "Will WORDij run with macOS Catalina?"
Answer: WORDij runs on Catalina after you have completed the procedures detailed here: WORDij Fix for Catalina
Question: "How do I preprocess Chinese text that has no white space between words?"
Answer: First of all, do not select the WordLink option to "Use Chinese filter." That option will only analyze characters, not words. There are several methods to tokenize Chinese. One is the Stanford segmenter. A tutorial on running the program can be found here: Segmenting Chinese Texts into Words for Semantic Network Analysis. Here is a stopword list to enter as a drop list in WORDij, WordLink: https://github.com/stopwords-iso/stopwords-zh/blob/master/stopwords-zh.txt. There is also an R package, JiebaR, that segments Chinese words. https://cran.r-project.org/web/packages/jiebaR/jiebaR.pdf
Question: "How do I change the contents of the drop list?"
Answer: Open in a text editer the droplist.txt file located in the Documentation folder. Delete and or add words. Follow the format of one word per line. Save the file with a new name, such as 'droplist2.txt.' Note that WORDij uses the term "drop list" to mean the same thing as "stopword list." See https://code.google.com/archive/p/stop-words/ for lists of stopwords in 29 different languages. In addition, here is a stopword list for Chinese: https://github.com/stopwords-iso/stopwords-zh/blob/master/stopwords-zh.txt.
Question: "How much text can WORDij handle?"
Answer: This depends on the memory installed in your machine. WORDij can typically processs files up to 500 megabytes or more in size. For such large files, a runtime typically take 20 minutes or so. If your files are on the order of 10s of megabytes, run times are a few minutes. If your file is of the size of a typical paper, or has 100 news stories, it will run in several seconds or less. The reason why WORDij is fast is because it is written in C++. You may have noted that the file to run the program is a .jar. Java is used only for the graphical user interface, which then calls the C programs.
Question: "Can I input CSV files into WORDij?"
Answer: Yes, this is a recently discovered undocumented feature. WordLink will ignore URLs in the file.
Question: "How do I graph my network?"
Answer: VISij in WORDij is good for small graphs, and for making movies of networks over time. Nevertheless, it is quite limited in functionality. One option is to import the .net file to Gephi. WORDij produces directed links, so choose the directed option in Gephi. NodeXL has a better graphing functionality. Import the .pr file into NodeXL. The graph on the main WORDij page was created in this way.
Question: "How do I compute standard network indices for WORDij output?"
Answer: UCINET is considered the gold standard for computing a wide range of network metrics, as well as preforming various transformations on network data. To use UCINET on WORDij output, import the .net file using the option for original Pajek format. To compute network statistics in NodeXL, import the .pr file.
Question: "What is the best way to identify groups of words that cluster together?"
Answer: NodeXL is a good choice for identifying groups of words via state-of-the-art cluster analysis. Another plus is its graphing features. It also enables computing a broad range of network indices. Import the .pr file from WORDij output, which contains a column for Word1, Word2, and Frequency.
Question: What is the meaning of Entropy in the output files types: .stw.csv and .stp.csv?"
Answer: Entropy is a measure of variability, like standard deviation. But, the latter requires the assumption of a normal distribution, while entropy does not. The particular kind of entropy WORDij uses is Shannon's Information Theory measure: 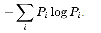 where pi is the probability of the word or word pair element occurring. This probability is the proportion of the total frequencies for the particular element. The summary value at near the top of file is an overall measure of variability in the words or word pairs that you can compare across different text files. See https://en.wikipedia.org/wiki/Entropy_(information_theory) and https://www.youtube.com/watch?v=NHAatuG0T3Q.
where pi is the probability of the word or word pair element occurring. This probability is the proportion of the total frequencies for the particular element. The summary value at near the top of file is an overall measure of variability in the words or word pairs that you can compare across different text files. See https://en.wikipedia.org/wiki/Entropy_(information_theory) and https://www.youtube.com/watch?v=NHAatuG0T3Q.
Question: "Can I run WORDij inside Dropbox?"
Answer: WORDij cannot run remotely on DropBox because it is a file storage device and not an operating system. WORDij needs an operating system, like Windows 10, or macOS Mojave and their Java JDK to run on for it to work.
Question: "How can I ask questions not covered here?"
Answer: Email James Danowski at jdanowski@gmail.com. He enjoys replying to any sort of question. He can also advise you on your research design involving network analysis. Please email him about how you are using WORDij.
